Functions hide
their workings in an implementation. Data types can be constructed with the
same idea in mind. Functions implementing operations on a structure supply an interface
for use by client code: other functions that use the structure, that is. Variables
used to build the structure and any helper functions provide a separate implementation. For a structure developed using non-OOP techniques, in Ada83 for example,
complete separation of the interface and implementation is possible by putting
the code in separate files.
OOP languages tend to rely less on physical
separation using key words such as public to
define parts of the interface with private and protected indicating elements of the implementation. OOP has reinvented separation of interface and implementation by calling it encapsulation: a class exposes public methods and encapsulates the rest.
There are two main advantages to this approach: implementation details can be
ignored when using the data type and different implementations of a structure
can be substituted without affecting the operations seen in the interface by
client code. Additionally, in some compiled languages a unit or package
containing the implementation can be modified and compiled separately without
the requirement to recompile client code. Only when the interface has changed is a rebuild required.
Perhaps a particular implementation works
efficiently for a small number of stored items but does not scale well to a
large number. Another implementation can accommodate a vast number of items but
carries an overhead that makes it less efficient than an alternative when used
with only a few. If one type can be substituted for the other without affecting
client code, changes to the software will be minimized when it becomes apparent
that a particular implementation is not up to the job. Time, cost, and a great
deal of frustration and unproductive effort will be saved.
Viewed in this way a data structure is
seen as an abstract data type (ADT). An ADT is defined by the
operations that can be carried out on it, the pre and post conditions of those
operations and the invariant condition of the ADT. Like the definition of a
relation discussed in Algorithms 3, a particular implementation does not figure
in an ADT definition. The basic operations on a stack of data
items, for example, are to push an item onto the top
of the stack and to pop an item off of it. Its
invariant can be defined as its size always being greater than or equal to zero
and less than or equal to a maximum size if one is specified.
Pre and postconditions
Some functions will only produce the
required result if certain conditions pertain when the function is called. For
stand alone functions that do not result in side effects on persistent data,
such conditions can only relate to restrictions placed on the input set. For
operations on a data structure the current state of the structure may also need
to be taken into account. These prerequisites for calling a function are its preconditions.
After the function exits another set of conditions
will apply. A statement of these postconditions is needed to
check that a particular implementation of the function works according to
requirements. For example, the pre and postconditions of a typical math square-root function defined in the style of VDM are:
SQRT(x:real)y:real
pre x >=0
post y*y = x and y >= 0
The input must be zero or positive; the
output when multiplied by itself must equal the input and be greater than or
equal to zero because sqrt() always returns the
positive square root. Alternatively the relationship between pre and post
conditions can be represented as a Hoare triple where and are
predicates and is a program that terminates when it is run.
The Vienna
Development Method (VDM) founded on Hoare Logic supplied a basis for
the realization of these concepts in software design but various less formal
specification languages are now available. OCL for example, an adjunct to the Unified
Modelling Language (UML), allows the use of formal English to define conditions
and invariants.
VDM, OCL etc. are typified as being formal
methods.Their representation as
Design by Contract has resulted in further deformalization although this may
not have been the intention of Bertrand Meyer who coined the metaphor to
represent the relationship between client code and code supplying a service.
A Stack ADT
After reviewing various formal and
semi-formal definitions on the www in relation to a stack (there are many), model based VDM looked too cryptic, algebraic based definitions likewise and OCL appeared
to lack precision. Perhaps formal English is the answer. Of course I am no
expert in any of these approaches so my judgement is open to doubt. The idea I
found most appealing used a series of operations in { } brackets (Wikipedia 2015). Applying this idea
to a stack ADT, a possible set of operations on a could be formulated as:
Stack(max_size: integer): r: Stack
pre true
post r = a new Stack instance
r.max_size = max_size
size(r) = 0
is_empty(r) = True
is_full(r) = False
invariant: size(r) >= 0
size(S: Stack): r: (0.. S.max_size)
pre true
post r = j - k where {S = Stack(), j * push(S, i), k * pop(S), j >= k}
{the sum of valid pushes - pops since S was created}
is_empty(S: Stack): r: bool
pre true
post r = (size(S) = 0)
is_full(S: Stack): r: bool
pre true
post r = (size(S) = S.max_size)
top(S: Stack): r: Item
pre not is_empty(s)
post r = i where {i = pop(S), S = push(S, i)}
{defines i, S after i has been popped off and pushed back on again}
push(S: Stack, i: Item): None
pre not is_full(S) and n = size(S)
post top(S) = i and size(S) = n + 1
pop(S: Stack): r : Item
pre not is_empty(S) and i = top(S) and n = size(S)
post r = i and size(S) = n - 1
The precondition true specifies the operation is valid for any state of a stack: there are no preconditions. An ADT invariant specifies conditions that are True for any instance and remain True throughout its lifetime irrespective of the operations carried out on it. It is therefore appropriate to place the invariant after the postconditions for initializing an instance.
With these operations in place a visualization of a stack with push and pop waiting to execute is as below:
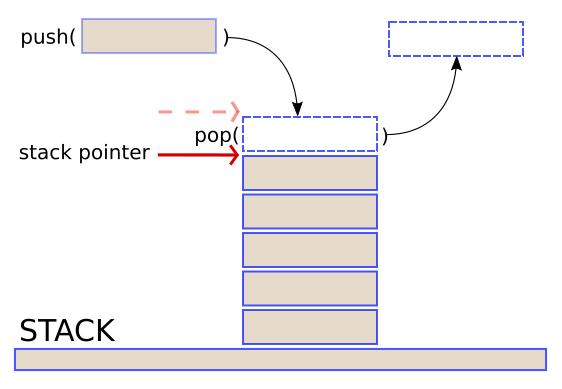
When the item on the left is pushed onto the stack and pop() is called that item will be the one on the top of the stack and
will be removed. This characteristic makes a stack a Last-In-First-Out
structure, a LIFO, as opposed to a queue which features First-In-First-Out,
a FIFO.
A traditional implementation of a stack without using any OOP techniques is best done in a separate file called 'stack.py'. The first step is to define a record to hold persistent data for the stack instance. By persistent I mean data that persists from one access of the stack to another (for data to persist from one run of a program to another it needs to be placed in backing storage i.e. put in a file saved to disk or some other medium).
An array to hold items in pushed order is
required. A stack pointer points to the next free location in the array. When
the array has zero based indexing, size and the value of stack-pointer are the
same: only a stack pointer is needed. Maximum size is the size of the array.
Using Python's record equivalent as before gets:
from array_types import array_
class stack:
def __init__(self, max_size):
self.array = array_(max_size)
self.SP = 0 # the stack pointer
self.max_size = max_size
Now define the stack operations:
def push(stack, item):
stack._array[stack.SP] = item
stack.SP += 1
def pop(stack):
stack.SP -= 1
return stack.array[stack.SP]
# etc.A complete set of operations is in 'stack.py' from the download project in Stacks.zip. Test scripts are also included. There are a couple points to note from the tests, in part resulting
from the characteristics of the underlying list type used to implement array_.
When there is an attempt to push an item
onto a full stack this overflow produces an exception. The
exception is raised before SP is incremented making the push() operation valid as far as it goes. However, when an underflow
occurs from popping an empty stack, the stack pointer is decremented to -1
before the invalid removal is attempted. There is no exception but this is
neither here nor there: the stack is already corrupted and will no longer
function correctly. The value of the stack pointer SP is also the size of the
stack and the ADT invariant is broken.
For those with
a belief that design by contract is the answer to all life's problems this may
be of no consequence: calling pop() on an empty stack is
in clear violation of pop's precondition. This is not my belief and these
problems will be dealt with a later article.
The
second point is that when items are popped off the stack the stack-pointer is
decremented but items are not actually removed. They will remain in the array
until an item is pushed into the space they occupy. For a limited number of
small objects this is not a problem but for a large structure replacing
references to objects with a reference to None in pop() might be required. A test file for 'stack.py' is in 'stack_test.py'
Testing the
stack
In a test file
possible syntax to use stack operations is:
from stack import * # import all stack's identifiers by name
a_stack = stack(6)
print('stack size:', size(a_stack), ' stack array:', a_stack.array)
push(a_stack, '||')
p = pop(a_stack)
print(empty(a_stack))
This is not at all bad and you could begin to
wonder what OOP is all about. A problem might come up though if
a queue was also required and someone had been foolish enough to
implement removing an item from the front of the queue as pop().
Then with
from stack import *
from queue import *
queue's pop()
would hide stack's pop()
and the wrong function would get called.
A way around this problem is to import all queue's
identifiers individually giving any that clash with stack's an alias:
from queue import join, pop as leave, .....
This alternative is open to error when there are
many identifiers. A way that avoids any possibility of error is to
import only the file name and prefix functions with it:
import stack
import queue
a_stack = stack.stack(6)
print('stack size:', stack.size(a_stack), ' stack array:', a_stack.array)
stack.push(a_stack, '||')
p = stack.pop(a_stack)
This alternative is acceptable for a few calls but
not when there are pages of code with many references to one or more
stacks,
I think. Perhaps it is time to see what OOP has on offer.
Summary
Here we have looked at the characteristics of
Abstract Data Types in general and in relation to a stack ADT. The
concepts of preconditions, postconditions and class invariants were
introduced. Testing the stack identified overflow and undeflow problems. There was also a problem when multiple imports were used one hiding the identifiers used in the other. Algorithms 11 will address these problems.
Reference
Wikipedia (2015) Abstract Data Type
[Online], 4 July 2015. Available at
https://en.wikipedia.org/wiki/Abstract_data_type (Accessed 26 July
2015).
[Algorithms 10: Abstract data types - Stack (c) Martin Humby 2015]