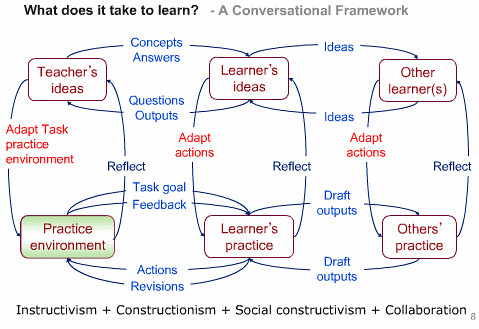
A Higher Education Academy sponsored distance learning workshop for computing and ICT was held at the Open University on Thursday 20 October 2011. The workshop addressed a number of different themes. These included internationalisation and the delivery of modules to different countries, professionalization and industry, models of distance learning, the use of technology and its accessibility.
The day was divided up into a number of different sessions, and I'll do my best to summarise them. I feel that blogging this event is going to be a little bit different from the previous times I have blogged HEA workshops since this time I was less of an observer and more of a participant. This said, I'll do my best!
Introduction and keynote
The event was introduced by Professor Hugh Robinson, head of the department of Computing at the Open University. Hugh briefly spoke about the history of the university and mentioned that Open means that students who enrol to courses do not necessarily have to have any qualifications. This connected to one of the university's themes: to be open in terms of people, places and ideas. Distance education enables education to be open in all these respects but it is apparent that due to the changes in the higher education sector, all institutions are to face challenges in the future.
Hugh's opening presentation gave way to Mike Richards keynote presentation about a new computing module entitled TU100, My Digital Life. Mike described some of the main topic areas of this new module which will for a common entry point to a number of degrees. This module addresses themes that are rather different to those that used to be on the computing curriculum, mostly due to the changes in technology and what is meant by a 'computer'.
Mike mentioned important subjects such as privacy and security, the notion of ubiquitous computing and what is meant by 'free', connecting to subject of open source software systems. Mike went on to say that the TU100 module contains some hardware that might once have been known as a 'home experiment kit'.
In the case of TU100 this is in the form of a programmable microcontroller board which can be configured in a way to work with different types of measurements and share the results with other people over the internet. Furthermore, the microcontroller (and connected software) can be developed using a visual programming language called Sense, which is a version of Scratch, a popular introductory programming environment developed by MIT.
Mike's presentation emphasised that distance education need not only begin and end with a virtual learning environment. A distance education module can contain a rich set of resources such as video materials and physical equipment that can be used to facilitate both understanding and debate. Mike emphasised the point that many issues that connect to the increasingly broad discipline of computing (broad because of its impact on so many other areas of human activity) is that some debates do not have right or wrong answers.
One thing is certain: technology has changed so many different aspects of our lives and will continue to do so in ways that we may not be able to expect. It's my understanding that one of the aims of TU100 is to highlight and uncover different debates and help students to navigate them. What was very clear is that computing education is so much more than just technology and getting it to do cool stuff. It's essential to understand and to consider how technology affects so many different aspects of our lives.
Morning session
The first presentation in the morning session was by Quan Dang from London Metropolitan University. Quan's presentation was entitled, 'blending virtual support into traditional module delivery to enhance student learning'. Quan emphasised how synchronous tools, such as on-line text chat could be used to create virtual 'drop in' sessions outside of core teaching hours to enable students to gain regarding subjects such as computer programming. Quan's presentation was very though provoking since it made me ask myself the question, 'what different tools and practices might we potentially adopt (at a distance) to help student get to grips with difficult issues such as debugging'. Debugging is something (in my humble opinion) that you can best learn by seeing how different people consume elements of the programming tools that are available through development environments. Getting a feeling of the different strategies that can be applied is something that can only be gained through experience, and technology certainly has the potential to facilitate this.
The following presentation, by Amanda Banks from the University of Manchester, was entitled 'advanced professional education in computer science'. Amanda spoke at some length about how a tool such as MediaWiki could be used to enable students to create useful materials that could be used with others. This presentation was also thought provoking: Wiki's can certainly be used within on-line modules to enable to student to generate materials for their own study, but Amanda's presentation made me consider the possibility that wiki-hosted material can be used between different module presentations as a way to facilitate debates about different ideas.
The final presentation was by Philip Scown, from Manchester Metropolitan University Business School. Philip's thought provoking presentation was entitled, 'the unseen university: full-flexible degrees enabled by technology'. Philip argued that technology can potentially allow different models of studying and learning, such as modules which don't have start dates, for instance. I can't do justice to Philip's talk within this space, so I do encourage you to have a look on the HEA website where I understand that his presentation slides are hosted.
First afternoon session
The afternoon session was started by Mark Ratcliffe, discipline lead for computing at the Higher Education Academy. Mark outlined the role of the HEA and then went on to describe funding opportunities and the role of a HEA academic associates. Mark then directed us to the HEA website for more information.
Distance education is one of those terms that can mean different things to different people, and this difference was, in part, highlighted by Mariana Lilley's first presentation of the afternoon that had the title, 'online, tutored e-learning and blended: three modalities for the delivery of distance learning programmes in computer science'. Mariana's presentation also represented a form of case study of a programme that is presented internationally by the University of Hertfordshire. It was interesting to hear about the application of different tools, such as Elluminate (now Blackboard Collaborate), QuestionMark Perception and VitalSource Bookshelf. This suggested to me the point that distance learning is now facilitated by a mix of different tools and made me question whether we have (collectively) identified best (or most effective) mix. Institutions have to necessarily explore technology in combination with pedagogic practice, and sharing case studies is certainly one way to understand something about what is successful.
Mariana's presentation was nicely complemented by Paul Sant's (in collaboration with his colleague Malcolm Sant) who was from the University of Bedfordshire. Paul's presentation was entitled, 'distance learning in higher education - an international case study'. Paul identified a number of challenges which included, 'how can we ensure that distance students remain engaged? How can we offer support in a way that meets their schedule and requirements?', and 'How can we ensure that the work performed by students meets their potential?' Paul mentioned tools such as the Blackboard VLE and synchronous tools by Horizon Wimba. Paul's presentation also helped to expose the subject of partnerships with international institutions.
Second afternoon session
The final session of the day was broadly intended to focus upon the needs of the student from two different perspectives. Steve Green from the Accessibility Research Centre, Teeside University kicked off this session by describing 'studying accessibility and adaptive technologies using blended learning and widgets'. Accessibility is an important subject since it enables students to make use of learning resources irrespective of how or where they may be studying (both in terms of their physical and technical environment), but also widens the way in which resources may be consumed, taking into account learners with additional requirements. Steve described how students create accessible widgets and their evaluation.
Steve's talk reminded me of a question that I was asked not so long ago, which is, given that distance legislation is now an international endeavour and the development of accessibility is supported by equality legislation, where do the boundaries lie in terms of offering support to students? The answer may depend on the issue of how partnerships are developed and function.
The final presentation of the day, entitled 'finding a foundation for flexibility: learner centred design' was by Andrew Pyper from the University of Hertfordshire. The underlying theme is that institutions need to understand the needs of their learners to best support them. Tools such as learner centred design, which is known to the interaction design and human-computer interaction communities, have the potential to create rich pictures which then potential guide the development of both learning experiences and technology alike.
Plenary
Towards the end of the day there was a bit of time to hold an open discussion about some of the different themes that the presentations had exposed. Many thanks to Amanda, Philip and Andrew for taking part. Some of the themes that came to my mind were the issues of tools and technology, internationalisation, industry and employability, and student skills. Points included that we need to be careful about our assumptions of the technology that students might have. Another important point is that one way to differentiate between different institutions might be in terms of the technologies that they use (and also how they use it).
We were also reminded about something called the Stanford Machine Learning course, which provoked some debate about 'free' (which relates back to Mike Richard's earlier TU100 presentation), and we were all directed towards the QAA Distance Learning precepts (many thanks to Richard Howley for bringing this to our attention).
Summary
All in all, it was a fun day! There were loads of questions asked following each of the sessions and much opportunity for talk and debate in between. I have to confess I was very relieved when the tea, coffees and sandwiches arrived on time, so thanks are extended to the Open University catering group.
It's tough, for me, to say what the highlight of the day was due to the number of very interesting thought provoking presentations. I certainly feel that there is always an opportunity to learn lessons from each other; it is clearly apparent that there are many different ways to approach distance education. Whilst there are many differences between institutions, similar issues are often grappled with, such as how to best make use of technology and ensure that students are offered the best possible level of support.