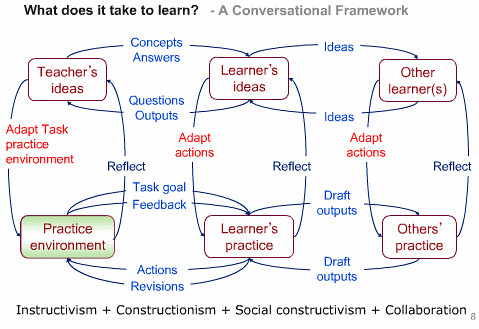
This blog post represents a review of the second International Education for All conference that I was lucky enough to attend in September 09. I originally intended to post a review earlier, but mitigating circumstances (which I hope will become clear at the end) prevented this.
Like the first conference, held in '07, this conference was also hosted at the University of Warsaw. The '07 conference represented a finale of an EU project, a collaboration between universities and other organisations from Germany, Poland, Estonia, Croatia and others (please forgive my poor memory!), but this one was slightly different.
Below I attempt to present a brief summary of some of the sessions that I attended. There were three parallel sessions, so I had to choose carefully. This is then followed by what I took away in terms of the themes of the conference.
Opening Keynote
The opening keynote was by Dianne Ryndak from the University of Florida. Dianne explored the topic of inclusion, particularly the differences between generalised and specialised education. Dianne explained how personalised support and learning activities could be provided as a part of general learning activities.
She went on to present a powerful description of two students: one who was educated within a segregated school, the other who was educated, with the provision of additional support, through a main stream (or general education) school. I remember her saying that 'education is a service that goes to the student, not a place where the student goes' and that education should be 'only as special as necessary'.
Although Dianne's presentation primarily related to high school education the themes she highlighted can be directly brought to bear on higher education too. Technology can be used as a way to help with the inclusion of people with disabilities main stream education. This said, teachers have a more important role where they need to be viewed as collaborators as well as educators.
Three dimensional solid science models for tactile teaching materials
I sometimes like to visit museums. One of the things that frustrate me is the sight of signs that say 'please do not touch!' This strikes me as particularly unfair when I discover sculptures in art galleries. Given that sculptors use their haptic sense when creating an object, it seems unfair to deny visitors the possibility of using this same modality.
Yoshinori Teshima, from the Digital Manufacturing Research Centre in Japan, gave an inspiring presentation where he showed a number of different models, ranging from abstract objects (such as polyhedra) through to hugely magnified representations of microscopic creatures that can only be seen under a microscope (imagine a microscoping monster the size of your fist!)
Yoshinori briefly spoke about the manufacturing methods, which included stereolithography and 3D printing using either plaster on nylon powder. His relief emphasised models of the earth and mars were fabulous.
It struck me that his models could be used by all students, regardless of visual abilities. It also struck me that the ultimate use of such models within the classroom depends ultimately upon the skills and the expertise of the teacher.
Talking Tactile Tablet
I have heard about tactile tablets before. This presentation demonstrated a product that was also included within the assistive technology exhibition that was also hosted at the conference.
I came away with two points from this presentation. Firstly, referring to three dimensional objects using two dimensional symbols is a skill that I take for granted. Secondly, it is now possible for educators to author their own tactile materials. We were shown how it was possible to create a small family tree. Audio materials were recorded using Audacity (Wikipedia), which were then associated to positions on a tablet. Corresponding tactile representations could be produced using embossers.
Opening Linux for the Visually Impaired
This presentation primarily focused upon a screen reader called Sue (Screenreader Usability Extensions) that was developed by the Study Centre for the Visually Impaired Students (SZS) based at the University of Karlsruhe, Germany. This presentation reminded me a little of a presentation of the Orca screen reader, made at the Aegis project dissemination event that I wrote about a couple of months ago.
One of the interesting things about Sue was that it could be connected to both a refreshable braille display (Wikipedia) (visiting this page was interesting, since it mentioned a new type of refreshable display called a rotating-wheel display) and a screen magnifier at the same time.
Although Sue could be considered to be 'yet another screen reader', having multiple versions of similar products is undeniably, in my view, a good thing. Competition between individual products, whether it is in terms of popularity or functionality can help their development and enhancement.
Distance Education and Training Programme on Accessible Web Design
I was drawn to this presentation due to involvement in the Open University Accessible online Learning and Fundamentals of Interaction Design courses. I was not to be disappointed. There were some strong echoes with these current courses, but I should say the curriculum is perhaps complementary.
The course was developed as a part of a European project called Accweb with the intention of creating distance learning materials that could address a need for a professional qualification or a certificate in accessible web design. The materials comprised of eighteen units which could be delivered through the ATutor VLE, amounting to the equivalent of 60 points of study.
Key elements of the curriculum included:
- Fundamentals of web accessibility
- Guidelines and legal requirements
- Assistive technologies
- Accessible content creation (which included issue such as methodology, evaluation, rich internet application and authoring tools)
- Design and usability (themes from human-computer interaction)
- Project development
The materials do not seem to be available through this site at the moment, but I hope they will be available in time.
Helping children to play using robots: IROMEC project experience
This presentation, by Francesca Caprino, outlined the IROMEC project, which is an abbreviation of Interactive Robotic Social Mediators as Companions and a sister project called the adapted robot project. Francesca began by describing play: what it is, what it can do and considered the effect of play deprivation on the development of children. Robots, it was argued, can help children with physical disabilities and other impairments participate in play activities.
The robots that were described were essentially toy robots that were modified to allow them to be controlled in different ways. Future research objectives included uncovering of new play scenarios, considering how to adapt or modify other robots and assessing the educative and therapeutic outcomes of robot assisted play interventions and developing associated guidelines.
Studying Sciences as a Blind Person: Challenges to AT/IT
Joachim Klaus introduced us to the Centre for the Visually Impaired Students, which seemed to have similarities to the Open University Office for Students with Disabilities (more information is available through the services for disabled students portal).
After presenting an overview of the centre, Joachim presented the ICC: International Camp on Computers and Communication. The ICC 'tries to make young blind and visually impaired students aware what technology can do for them, which computer skills they have to have, where they should put efforts to enhance their technical skills, the level of mobility as well as their social skills'. Using and learning to use assistive technologies can be difficult. This international camp, which is held in different countries, can help people become more skilled at using assistive technologies, thus removing substantial barriers to access.
Improving the accessibility of virtual learning environments using the EU4ALL framework
During the conference, I gave a short talk about the EU4ALL project I am working on. The presentation focussed on an architecture that the project has been creating and how it can improve the accessibility of services that are delivered to students. The architecture takes into consideration a number of different stakeholders, each of which has a responsibility in helping to deliver accessibility. My slides are available on-line through the Open University Knowledge Network (presentation information).
At the same time as my presentation, my colleague Elisabeth Unterfrauner from the Centre for Social Innovation, Technology and Knowledge, Vienna, was presenting her research, the socio-economic situation of students with disabilities, also carried out within the EU4ALL project.
Fostering accessibility through Design4All education in mainstream education
Continuing the theme of EU projects, Andrea Petz gave an interesting presentation about universal design, or Design4All. Andrea has been involved with EDeAN, and abbreviation for the European Design for All e-Accessibility Network. EDeAN has studied how D4ALL is covered or treated in different universities across Europe and has helped to guide the development of a masters programme.
Andrea began her presentation by saying that D4ALL is not design for the average, but for the widest possible group of users and went on to talk about the principles of universal design (Wikipedia):
- Equitable use
- Flexibility in use
- Accessible information
- Tolerance for errors
- Simple and intuitive
- Low physical effort
- Size and space for approach and use
Andrea pointed us towards a conference called the International Conference on Computers Helping People with Special Needs (IICHP).
Inclusive science strategies
Greg Stefanich added two more to Andrea's list of principles, namely:
- Build a community of learners
- Create a positive instructional climate, i.e. one that is welcoming.
Greg also connected his talk to the theme of inclusive education by saying 'a person in a regular class room setting will have better relationships with the general public, family and be employed' and emphasised the view that inclusion of all students will have no real consequence on other students. An important point is to spend time to get to know the needs of individuals so they can be effectively supported.
Foreign language courses for students with hearing impairments
Ewa Domagała-Zyśk talked about her experience of teaching English to hearing impaired students. Her presentation made me reflect on my own experience of using the virtual world SecondLife (although Ewa's presentation was mostly about why teaching foreign languages is a good thing and what some of the challenges might be).
Quite some time ago, I was adventurous enough to visit a couple of 'Polish speaking' virtual bars where I tried to interact, using text, with some of the 'regulars' and found myself totally lost. This experience showed me that this was an interesting and predominately unthreatening way to help to learn (and understand) written language. It did make me wonder whether virtual worlds (in combination with real-word assistance, of course), might be an interesting way to expose people to new languages. The issue of whether such environments promote the creation of new dialects is, of course, a whole other issue.
Educational practices towards increasing awareness among academic teachers
Dagmara Nowak-Adamczyk (or one of her colleagues) spoke about the DARE project, a disability awareness project. The project website states, 'The long-term objective of the project and the DARE Consortium is raising public awareness of disability and the way people with disabilities function in modern (knowledge-based) society'. The project has produced some training materials which are currently being evaluated.
Access for science students with disabilities in an open distance learning institution in South Africa
I was particularly looking forward to this presentation since its title contained particularly interesting themes. Eleanore Johannes, from the University of South Africa, spoke about different models of disability, introduced us to the Advocacy and Resource Centre for Students with Disabilities (ARCSWiD) office and spoke of some of the challenges that students face: funding, electricity, inaccessibility web pages and training. She also described a qualitative research project that is exploring the experiences of science students with disabilities that is taking place over a period of three years.
No contradiction : Design4All and assistive technologies
Michaela Freudenfeld introduced the INCOBS web portal that provides information about assistive technologies that are available in Germany. The INCOBS portal has the objective of carrying out market surveys of products and services, testing of assistive devices and workplace technologies, evaluating the accessibility of software applications and offer seminars for facilitators and advisors.
Understanding educational needs of students with psychiatric disabilities
Enid Weiner, from the Counselling and Disability Services, York University, Canada, gave an impressive hour long talk on the theme of mental health difficulties. The subtitle of her presentation was 'making the invisible more visible'.
Enid spoke about a number of interesting related themes, such as different illnesses, the effect of medication and that some illnesses can have an episodic nature, which may cause the place of learning to be slower or take place over an extended period. Accommodations are to be made on a case by case basis.
Enid emphasised the importance of a 'community of support' and said how important it is for educational providers not to 'get hung up' on an individual diagnosis and instead focus on individual accommodations i.e. what learners need to study.
Environmental influences on participation with disabilities: a Sri Lankan perspective
This was an interesting presentation since it presented a different perspective. Samanmali Kularatne outlined the situation in Sri Lanka and then described a study that is aiming to explore the experiences of children with disabilities in mainstream schools.
The study adopts a qualitative approach. Interviews are carried out in class rooms, which are then transcribed and subjected to thematic analysis. The participants include children, teachers, parents and non-participative observers. Themes identified included: attitudes, values and beliefs, support and relationships, products and technology, natural and built environment.
The conclusion was that inclusion is not really a reality and that there is a lack of resources. The actions resulting from the study includes further communication with educational authorities, an awareness programme for parents and launching a project to try to initiate more inclusion.
How AT can help with learning maths for people who are print disabled
The presentation and manipulation of mathematical notation is a perennial problem. When some mathematical expressions are translated into spoken language ambiguities can easily arise. One proposed solution is to make use of the LaTeX (Wikipedia) language.
The challenge is not just technical. Acceptance of technology relates to the willingness of learners to accept technological solutions and effectiveness of teachers to communicate their potential benefits. It also relies upon educators having both the time and wiliness to understand different tools.
Considering different definitions of disability
Paweł Wdówik from the University of Warsaw Office for Persons with Disabilities spoke about the different definitions of disability and the differences that exist between primary and secondary education. Paweł highlighted that through the medical model, if you don't have a medical model, then a disability is not likely to exist. As a result, people who do have disabilities are likely to slip through the system. Paweł emphasised that the views of the individual should always be fundamental.
Working towards inclusive education in Europe
Andrea Watkings from the European Agency for Development in Special Needs Education spoke about the different agency projects and mentioned the UNESCO Salamanca statement and asked the question, 'how do we change our systems so they are inclusive from the beginning?' and made the point that inclusion needs to take account of all peoples and groups. Amanda emphasised that inclusion is a process, not a state.
Closing Keynote
The final presentation of the conference was made by Yvonne Bonner, Reggio Emilia, Italy. Yvonne presented a range of very thought provoking images. She asked the question, 'why work in this area?' She answered philosophically (and, of course, I paraphrase) that by working in this area you are considering (and hopefully challenging others to enhance) the rights of all people. It was a great way to close the conference.
Conference themes
One of the ways that this conference differed from the previous event was that there were more distinct themes. Whereas the previous event focused quite a lot on an EU project that had just concluded, this conference I felt was slightly more wide ranging (but this could be cause I was more attuned to what to look out for).
One of the more prominent theme were debates surrounding inclusion or exclusion, or more specifically, how to help ensure that people with additional needs could be effectively brought into mainstream education. This theme was clearly articulated within the opening and closing keynote speeches. There are differences between countries (and the models of disability that are applied). Sharing understanding of definitions was certainly a subject that was considered to be important.
Another theme was the need to listen to the individual. I recall two projects that are aiming to learn more about the experience of individuals.
Quite a few of the presentations related to on-going projects and programmes. Ideally I would have liked to go away with a more fuller set of conference proceedings to help me remember what was said and recall the arguments that were presented. Hopefully, as the conference series proceeds, this may be something that the organisers may consider, but hopefully without detracting from an underlying sense that delegates are happy to discuss, share and learn from each others practice.
Addendum
After the conference ended I had some free time. It was suggested that a fun thing to do would be to go hiking in the Tatra mountains. I had been told a lot about a town called Zakopane and how it once exerted a strong draw for artists and Bohemians, and how a special cheese was likely to be sold everywhere in the town. I was not to be disappointed. As well as having extraordinary mountains and restaurants, tourists walking down the main street would stumble across cheese purveyors (Wikipedia) very thirty or so metres.
My choice of words is no accident, but instead I was embroiled in one. Rather than literally stumbling across cheese sellers, I literally stumbled down the side of a mountain and broke my arm (although I should add that the stumble was a relatively modest one of about forty or so centimetres). Visiting the accident and emergency ward was an experience, where a sharp witted paramedic, upon hearing that I was from the UK asked, 'were you walking on the wrong side of the path?' There were more jokes, but their charm has long since worn away!
The upshot of the accident was that I found myself temporarily disabled, my dominant arm immobilised in plaster. It all came as a bit of a shock. Simple tasks suddenly became trials of patience and took considerable longer, if I could figure out how do them at all. Shoe laces became a liability and shirt buttons became almost impossible. I had to go about cancelling events and activities that were scheduled for the time after I was to return to the UK.
Upon return to the UK, my motivation levels nose dived. I quickly recalled the universal design principles when doors became difficult to open and jars and cans a frustrating challenge. I also had entered the UK health system, but I had no real sense of who I should ask about information about things. Whilst monolithic institutions are there to help, individuals are necessary to provide support and peace of mind.
Despite my frustrations, I still had an overwhelming desire to do stuff. Although I wasn't able to attend a weekend meeting I was scheduled to attend, one of my colleagues from the University of Leeds helped me to participate. Using Skype text chat, it was possible to take part in a short group discussion activity which helped to lift my mood. This showed me what a positive impact technology can by providing effective alternative ways of communication. It also distinctly underlined on of the conference themes: the importance (and power) of inclusion.
I think I'm on the mend now, but I understand it's going to take some time. All in all, the trip (both to the conference, and over a part of mountain) was an interesting experience. I've certainly learnt a few things.