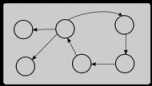
This is a second blog entry about how Moodle manages its blocks (which can be found either at a site level or at a course level). In my previous post I wrote about the path of execution I discovered within the main Moodle index.php file. I discovered that the version of Moodle that I was using presented blocks using tables, and that blocks made use of some interesting object-oriented features of PHP to create the HTML code that is eventually presented to the end user.
This post has two objectives. The first is to present something about the database structures that are used to store information about which blocks are stored where, and secondly to explore what happens when an administrator clicks on the various block editing functions. The intention behind this post is to understand Moodle in greater detail to uncover a little more of how it has been designed.
Blocks revisited
Blocks, as mentioned earlier, are pieces of functionality that can sit on the left hand or right hand borders of courses (or the main Moodle site page). Blocks can present a whole range of functions ranging from news items through to RSS feeds.
Blocks can be moved around within a course page with relative ease by using the Moodle edit button. Once you click on ‘edit’ (providing it is there and you have the appropriate level of permissions), you can begin to add, remove and move blocks around using a couple of icons that are presented. Clicking on the left icon moves the block to the left hand margin, clicking the down arrow icon changes its vertical position and so on.
One of my objectives with this post is to understand what happens when these various buttons are clicked on. What I am hoping to see are clearly defined functions which will be called something like moveBlockUp, moveBlockDown or deleteBlock.
Perhaps with future versions it might be possible to have a direct manipulation interface (wikipedia) where rather than having buttons to press, users will be able to drag blocks around to rapidly customise course displays. Proposing ideas and problems to be solved is a whole lot more easier than going ahead and solving them. Also, to happily prove there’s no such thing as an original thought, I have recently uncovered a Moodle documentation page. It seems that this idea has been floating around since 2006.
Before I delve into trying to uncover how each of the Moodle block editing buttons work, it is worthwhile spending some time to look at how Moodle remembers what block is placed where. This requires looking at the database.
Remembering block location
I open up my database manipulation tool (SqlYog) and begin to browse through the database tables that are used with Moodle. I quickly spot a bunch of tables that contain the name block. One that seems to be particularly relevant is a table called block_instance.
The action of creating a course (and adding blocks to it) seems to create a whole bunch of records in the block_instance. Block_instance appears to be the table that Moodle uses to remember what block should be displayed and when.
The below graphic is an excerpt from the block_instance data table:
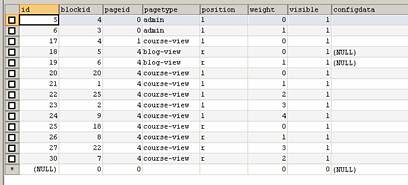
The field weight seems to relate to the vertical order of blocks on the screen (I initially wondered whether it related to, in some way, some kind of graphical shading, thinking of the way that HTML uses the term weight). Removing a block from a course seems to change the data within this table.
The blockid seems to link each entry within block_instance to data items held within the Block table:

The names held within the name field (such as course_summary) are connected to the programming code that relates to a particular block. The cron (and the lastcron) relate to regular processes that Moodle must execute. With the default installation of Moodle everything is visible, and at the time of writing I have no idea what multiple means.
Returning to block_instance, does the pageid field relate to the id used in the course? Looking at the course table seems to add weight to his hypothesis.
I continue my search for truth by rummaging around in the Moodle documentation, discovering a link to the database schema and uncover some Block documentation that I haven’t seen before (familiarity with material is a function of time!) This provides a description of the block development system as described by the original developer.
Knowing that these two tables are now used to store block location my question from this point onwards is: how does this table get updated?
Database updates
To answer this question I applied something that I have called ‘the law of random code searching’: if you don’t know what to look for and you don’t know how things work, carry out a random code search to see what the codebase tells you. Using my development environment I search to find out where the block_instance datatable is updated.
Calls to the database to be spread out over a number of files: blocks, lib, accesslib, blocklib, moodlelib, and chat/lib (amongst others). This seems to indicate that there is quite a lot of coupling between the different sections of code (which is probably a bad thing when it comes to understanding the code and carrying out maintenance).
Software comprehension is sometimes an inductive process. Occasionally you just need to read through a code file to see if it can yield any clues about its design, its structure and what it does. I decided to try this approach for each of the files my search results window pointed to:
Accesslib
Appears to access control (or permission management) to parts of Moodle. The comments at the top of the file mention the notion of a ‘context’ (which is a badly overloaded word). The comments provide me no clue as to the context in which context is used. The only real definition that I can uncover is the database description documentation which states, ‘a context is a scope in Moodle, for example the whole system, a course, a particular activity’. In AccessLib, there are some hardcoded definitions for different contexts, i.e. CONTEXT_SYSTEM, CONTEXT_USER, CONTEXT_COURSECAT and so on.
The link to the blocks_instance database lies within a huge function called create_context which updates a database table of the same name. I’ve uncovered a forum explanation that sheds a little more light onto the matter, but to be honest, the purpose of these functions is going to take some time to uncover. There is a clue that the records held within the context table might be cached for performance reasons. Moving on…
Moodlelib
Block_instance is mentioned in a function named remove_course_contents which apparently ‘clears out a course completely, deleting all content but don’t delete the course itself’. When this function is called, modules and blocks are removed from the course. Moodlelib is described as ‘main library file of miscellaneous general-purpose Moodle functions’ (??), but there is a reference towards another library called weblib which is described as ‘functions that provide web output’.
Blocks
A comment at the top of the blocks.php file states that it ‘allows the admin to configure blocks (hide/show, delete and configure)’. There is some code that retrieves instances of a block and then deletes the whole block (but in what ‘context’ this is done, at the moment it’s not clear).
Blocklib
The file contains the lion’s share of references to the block_instance database. It is said to include ‘all the necessary stuff to use blocks in course pages’ (whatever that means!) At the top there are some constants for actions corresponding to moving a block around a course page. Database calls can be found within blocks_delete_instance, blocks_have_content, blocks_print_group and so on. The blocks_move_block seems to adjust the contents of the database to take account of moment. There also appears to be some OO type magic going on that I’m not quite sure about. Perhaps the term ‘instance’ is being used in too many different ways. I would agree with the coder: blocklib does all kinds of ‘stuff’.
Lib files
Reference to block_instance can be found in lib files for three different blocks: chat, lesson and quiz. The functions that contain the call to the database relate to the removing of an ‘instance’ of these blocks. As a result, records from the block_instance table are removed when the functions are called.
So, what have I learnt by reading all this stuff? I’ve seen how the database stores stuff, that there is a slippery notion of a course context (and mysterious paths), and know the names of some files that do the block editing work, but I’m not quite sure how. There is quite a lot of complexity that has not yet been uncovered and understood.
Digressions
I have a cursory glance through the lib folder to see what else I can discover and find an interestingly named script file entitled womenslib.php. Curious, I open it and see a redirect to a wikipedia page. The Moodle developers obviously have a sense of humour but unfortunately mine had failed! This minor diversion was unwelcome (humour failure exception), costing me both time and ‘head’ space!
Bizarrely I also uncover seemingly random list of words (wordlist.txt) that begins: ‘ape, baby, camel, car, cat, class, dog, eat …’ etc. Wondering whether one of the developers had attended the famous Dali school of software engineering, I searched for a file reference to this mysterious ‘wordlist’.
It appeared that our mysterious list of words was referenced in the lib\setup.php file, where a path to our worldlist was stored in what I assumed to be a Moodle configuration variable. How might this file be used? It appears it is used within a function called generate_password.
Thankfully the developers have been kind enough to say where they derived some of their inspiration from. The presence of the wordlist is explained by the need to construct a function to create pronounceable automatically generated passwords (but perhaps only in English?)
This was all one huge digression. I pulled myself together just enough to begin to uncover what happens when a user clicks on either the block move up, down, or delete buttons when a course is running in edit mode.
Button click action
Returning to the task in hand, I add two blocks (both in the right hand column, and one situated on top of the other) to my local Moodle site with a view to understanding that function code that contributes to the moveBlockUp and deleteBlock functionality.
I take a look at the links that correspond to the move up and the delete icons. I notice that the action of clicking sends a bunch of parameters to the main Moodle index.php. The parameters are sent via get (which means they are sent as a part of the hypertext link). They are: instanceid (which comes straight out of the block_instance table), sesskey (which reminds me, I really must try to understand how Moodle handles sessions (wikipedia) at some point), and a blockaction parameter (which is either moveup or delete in the case of this scenario).
The question here is: what happens within index.php? Luckily, I have a debugger that will be able to tell me (or, at least, help me!)
I log in as an administrator through my debugger. When I have established a session, I then add some breakpoints on my index.php code and launch the index.php code using the parameters for ‘move activity upwards’.
Index.php begins to execute, and a call to page_create_object is made. It looks like a new object is created. An initialisation function within the page_base class is called (contained within pagelib). A blocks_setup function is called and block positions from the block_instance database is retrieved. After some further tracking I end up at a function called blocks_execute_url_action. The instanceid is retrieved and a call is made to blocks_execute_action where the block action (moveup or delete) is passed in as a parameter with the block instance record that has just been retrieved from the database.
In blocks_execute_action a 'mother of all switch statements' makes a decision about what should be done next. After some checks, two update commands to the database are issued through the update_record function updated weight values (to change the order of the respective blocks). With all the database changes complete, a page redirect occurs to index.php. Now that the database has the correct representation of where each block should be situated index.php can now go ahead and display them.
Is the same mechanism used for course pages?
A very cursory understanding tells me that the course/view.php script has quite a lot to do with the presentation of courses, and at this point gathering an understanding of it is proving to be elusive. Let’s see what I can find.
Initially it does seem that the index.php script controls the display of a Moodle site and course/view.php script does control the course display. Moving the mouse over the ‘move block up’ icons reveals a hyperlink to the view.php script with get parameters of: id (which corresponds to the course number held within the course data table), instance id (which corresponds to a record within the block_instance table) and sesskey and blockaction parameters (as with index.php).
To get a rough understanding of how things work, I do something similar as before: open up a session through my debugger and launch the view.php with this bunch parameters. The view.php course is striking. It doesn’t seem to be very long and nor does it produce any HTML so it looks like there’s something subtle going on.
In view.php, there are some parameter safety checks, followed by some context_instance magic, checking of the session key followed by calls to the familiar page_create_object (mentioned in the earlier section). Blocks_setup is then called, followed by blocks_get_by_page_pinned and blocks_get_by_page which asks the database which blocks are associated to this particular page (which is a course page).
Like earlier, there is a call to blocks_execute_url_action when updates the database to carry out the action that the administrator clicked on. At the end of the database update there is a redirect. Instead of going to index, the redirect is to view.php along with a single parameter which corresponds to the course id.
This raises the question: what happens after the view.php redirect?
Redirect to view.php
When view.php makes a call to the database to get the data that corresponds to the course id number it has been given. There is then a check to make sure that the user who is requesting the page is logged into Moodle and eventually our old friends page_create_object and blocks_setup are called, but this time since no buttons have been clicked on, we don’t redirect to another page after we have updated the database.
Towards the end of view.php we can begin to see some magic that begins to produce the HTML that will be presented to the user. There is a call to print_header. There is then a script include (using the PHP keyword ‘required’) which then creates the bulk of the page that is presented to the user, building the HTML to present the individual blocks. When running within my debugger, the script course/format/weeks/format.php was included. The script that is chosen depends on the format of the course that has been chosen. When complete, view.php adds the footer and the script ends.
Summary
So, what have I learnt from all this messing about?
It seems that (broadly speaking) the code used to move blocks around on the main Moodle site is also used to move blocks around on a course page, but perhaps this isn’t too surprising (but it is reassuring). I still have no idea what ‘pinned blocks’ means or what the corresponding data table is for but I’m sure I’ll figure it out in time!
Another thing that I have learnt is that the view course and the main index.php pages are built in different ways. As a result, if I ever need to change the underlying design or format of a course, I now know where to look (not that I ever think this is something that I’ll need to do!)
I have seen a couple of references to AJAX (MoodleDocs) but I have to confess that I am not much wiser about what AJAX style functionality is currently implemented within the version of Moodle I have been playing with. Perhaps this is one of those other issues that will become clearer with time (and experience).
One thing, however, does strike me: the database and the user interface components are very closely tied together (or closely coupled) which may make, in some cases, change difficult. One of the things that I have on my perpetual ‘todo’ list is to have a long hard look at the Fluid Project, but other activities must currently take precedence.
This pretty much concludes my adventure into the world of Moodle blocks. There’s a whole load of Moodle related stuff that I hope to look at (and hopefully describe) at some point in the future: groups, roles, contexts, and forums. Wish me luck!
Acknowlegements: Image from lifeontheedge, licenced under Creative Commons.