Information behaviour of the researcher of the future. Written in 2007 (published 11 January 2008). Reviewed in 2011.
Part of the Week 1 jollies for H800.
(This picks up where I left off in the Forum Thread)
After a year of MAODE, a decade blogging and longer keeping journals (and old course work from both school and uni I might add) I feel I can tap into my own first, second, third or fourth take on a topic.
Increasingly, where this is digitised my preferred learning approach is to add to this information/knowledge, often turning my ideas inside out.
We are yet to have a ‘generation,’ (a spurious and loose term in this context) that has passed through primary, secondary and tertiary education ‘wired up’ to any consistent degree from which to gather empirical research. Indeed, I wonder when things will bottom out, when we’ve gone the equivalent journey of the first horseless-carriage on the Turnpikes of England to the 8 lanes in both directions on the M1 south of Leicester – or from the Wright Brothers to men on the moon.
I’d like to encourage learners to move on from copying, or cutting and pasting in any form, to generating drafts, and better drafts of their take on a topic, even if this is just a doodle, a podcast or cryptic set of messages in a synchronous or asynchronous discussion i.e. to originate.
I lapped up expressions such as Digital Natives, an expression/metaphor only that has been debunked as lacking any basis in fact.
I fear this is the same when it comes to talking about ‘Generation X, Y or Z.’ It isn’t generational, it is down to education, which is down to socio-economic background, wealth, access (technical, physical, geographic, as well as mental), culture, even your parent’s job and attitude.
My 85 year old Father-in-law is Mac ready and has been wired to the Internet its entire life; does this make him of this ‘Generation?’
If x billion struggle to find clean drinking water and a meal a day, where do they stand?
They’ve not been born on Planet Google, so don’t have this generational opportunity.
I find it short sighted of the authors not to go for a ‘longitudinal’ (sic) study. It strikes me as the perfect topic of a JISC, Open University, BBC tie in, the filming part funding the research that is then published every three years for the next thirty, for example.
Trying to decide who is Generation X, or Generation Y or the ‘Google Generation’ strikes me as fraught as trying to decide when the islands we inhabit became, or could have been called in turn England, Scotland, Wales, Great Britain or the United Kingdom.
We could spend an unwarranted amount of time deciding who is in and who is out and not agreed.
We can’t it’s like pouring water through a sieve. The creator of IMBD, a computer geek and film buff was born in the 60s (or 70s). Highly IT literate, then as now, he is not of the ‘Google Generation’ as defined as being born after 1993, but is surely of the type?
Personally I was introduced to computers as part of the School of Geography initiative at Oxford in 1982.
Admittedly my first computer was an Amstrad, followed by an early Apple, but I’ve not been without a computer for the best part of thirty years. I can still give my 12 year old a run for his money (though he does get called in to sought our browser problems).
And should this report be quoting Wikipedia?
Surely it is the author we should quote if something is to be correctly cited; anyone could have written this (anyone did).
Reading this I wonder if one day the Bodleian Library will be like a zoo?
The public will have access to view a few paid students who recreate the times of yore when they had to read from a book and take notes, and look up titles in a vast leather-bound tome into which we strips of paper were intermittently stuck. (not so long ago).
Is there indeed, any point in the campus based university gathered around a library when all his millions, or hundreds of millions of books have been Googliefied?
Will collegiate universities such as Oxford, Cambridge, Bristol and Durham (Edinburgh and Dublin? Harvard ?) become even more elite as they become hugely expensive compared to offerings such as the Open University?
There may be no limit to how much and how fast content can be transmitted … the entire Library of Congress in 3 seconds I am told, but there are severe limits to how much you can read and remember, let alone make sense of and store.
Is this not the next step?
To rewire our minds with apps and plug-ins? I smile at the idea of ‘power browsing’ or the new one for me ‘bouncing’ the horizontal drift across papers and references rather than drilling vertically, driven by a reading list no doubt.
I can give a name to something I did as an undergraduate 1981-1984. Reading Geography I began I the Map room (skipped all lectures) and then spent my morning, if necessary moving between libraries, particularly the Rhodes Library and Radcliffe Science Library, by way of the School of Geography Library, of course, and sometimes into the Radcliffe Camera or the PPE Reading Rooms.
I bounced physically.
I bounced digitally online as a preferred way of doing things. Though this often leaves me feeling overwhelmed by the things I could read, but haven’t read, that I’d like to read. Which is good reason ONLY to read the latest paper, to check even here if the paper we are asked to read has not already been superseded by this or fellow authors.
Old digitised news keeps like a nasty smell in the wind?
Users are promiscuous, diverse and volatile and it is clear that these behaviours represent a serious challenge for traditional information providers, nurtured in a hardcopy paradigm and, in many respects, still tied to it. (p9)
The problem with the short read and low tolerance of readers is the way papers have thus far gone from print version to digital version without, yet, thorough transmogrification.
We await new acceptable ways to write, and submit and share knowledge that is less formal and to anyone versed in reading online, digestible.
All authors for the web would do well to read Jakob Nielsen on web usability.
There is a way to do it. If it looks like it belongs in a journal or book, you are getting it wrong
Do the authors appreciate that labelling the behaviour ‘squirreling’ is self-fulfilling?
It normalises the behaviour if anyone reads about it. Whilst metaphors are a useful way to explain, in one person’s words, what is going on, such metaphors soon become accepted as fact.
There is a running debate across a series of article in the New Scientist on the way humans think in metaphors (good, can’t help it), and how ideas expressed as metaphors then set unfounded parameters on how we think (not so good, and includes things like the selfish gene, competition and so on).
This dipping, bouncing and squirreling, horizontal browsing, low attention span, four to eight minute viewing diverse ‘one size does not fit all’ individual would make for an interesting cartoon character. I wonder if Steven Appleby or Quentin Blake would oblige. ________________________________________________________________________________
Why ‘huge’ and why ‘very’ ? Qualify. Facts. Evidence. And why even, 'very, very.' This isn't academic writing, it's hear say and exaggeration.
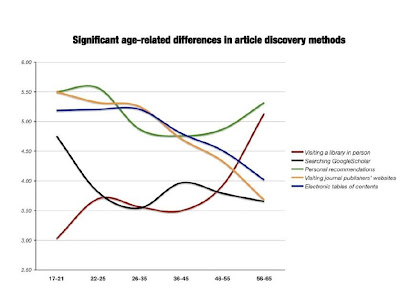
There’s a category missing from the graph – branded information, such as Wikipedia, or Harvard Business Publication, Oxford or Cambridge University Press and Blackwell’s, to name put a few.
Where so much information is available, and so many offerings on the same topic, the key for anyone is to feel they are reading a reliable source.
The point being made later about ‘brand’ presence for BL … something we will see more of with the commercialisation of information. Even Wikipedia cannot be free for ever, while the likes of Wikileaks, for its mischief making and spy-value will always be funded from nefarious sources.
There are very very few controlled studies that account for age and information seeking behaviour systematically: as a result there is much mis-information and much speculation about how young people supposedly behave in cyberspace. (p14)
Observational studies have shown that young people scan online pages very rapidly (boys especially) and click extensively on hyperlinks - rather than reading sequentially. Users make very little use of advanced search facilities, assuming that search engines `understand’ their queries. They tend to move rapidly from page to page, spending little time reading or digesting information and they have difficulty making relevance judgements about the pages they retrieve. (p14)
Wikipedia and YouTube both exhibit a marked age separation between viewers of content (mainly 18-24s) and content generators (mainly 45-54s and 35-44s respectively). (p16, ref 17)
‘there is a considerable danger that younger users will resent the library invading what they regards as their space. There is a big difference between `being where our users are’ and `being USEFUL to our users where they are’.
Surely it would be easy to compare a population that have access and those who do not?
Simply take a group from a developed, rich Western nation and compare them to a group that are not, that don’t have the internet access, video games or mobile phones.
REFERENCE
Information behaviour of the researcher of the future. UCL 11 JAN 2008