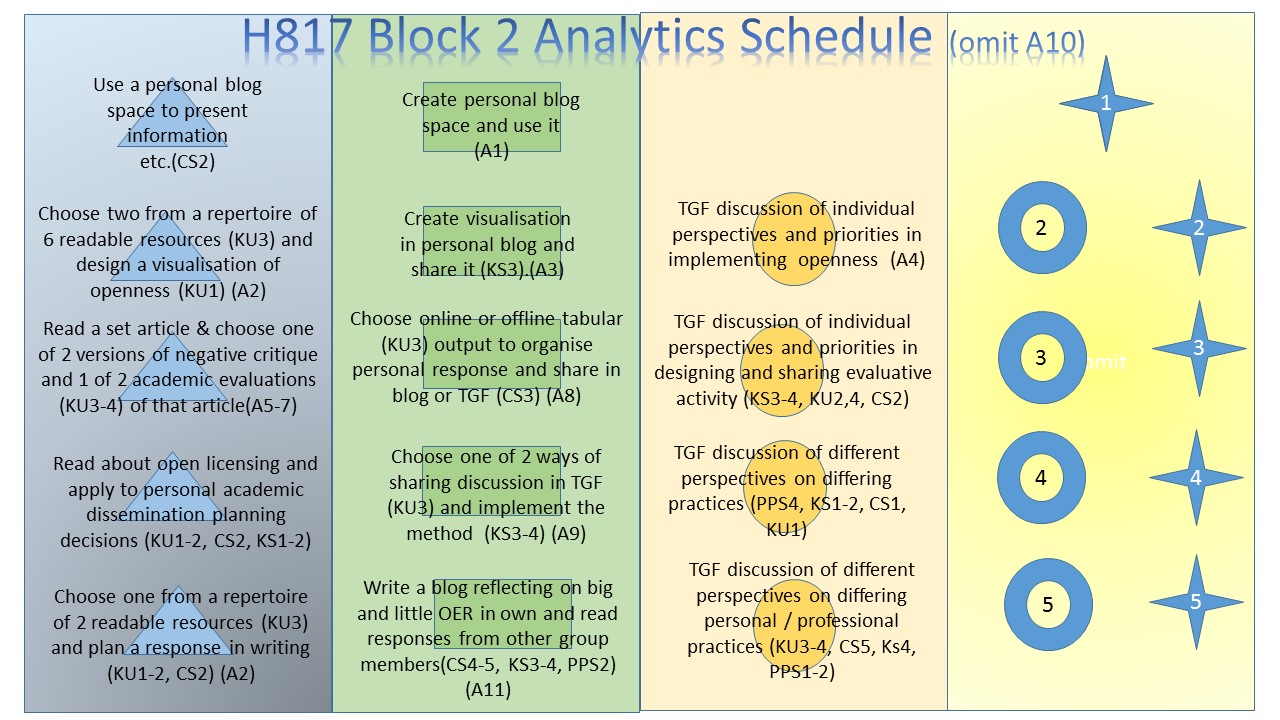
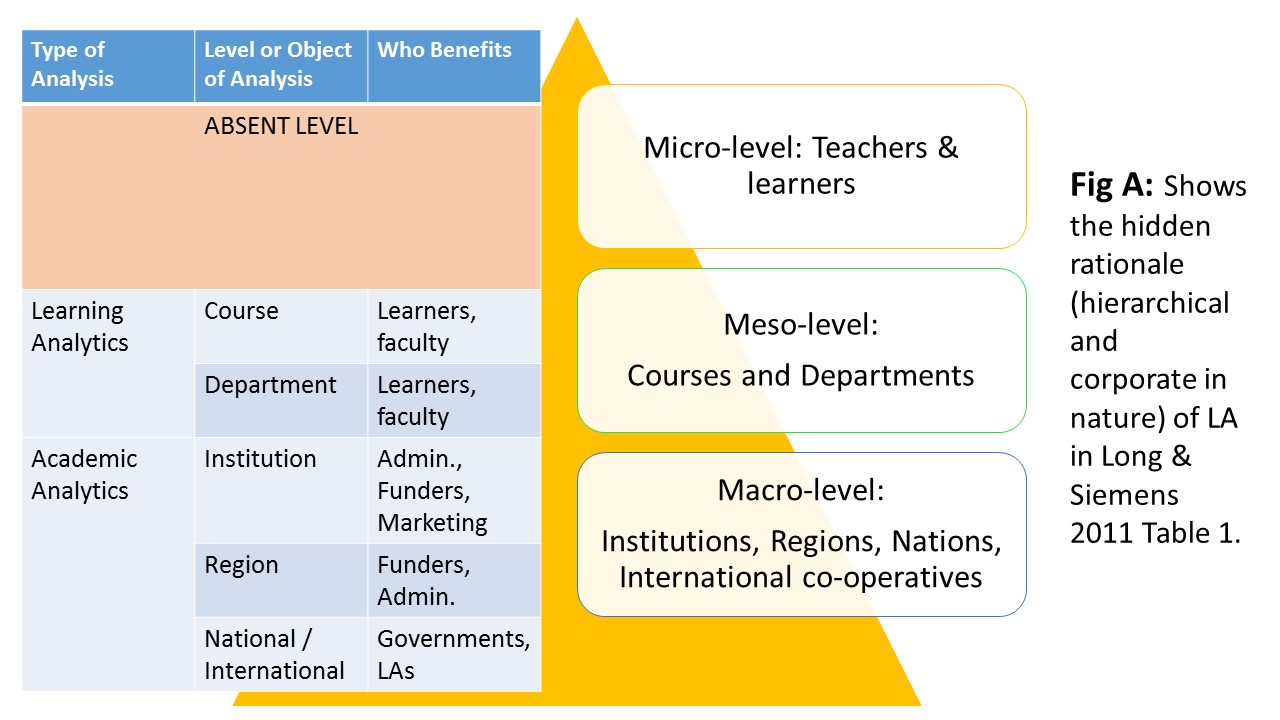
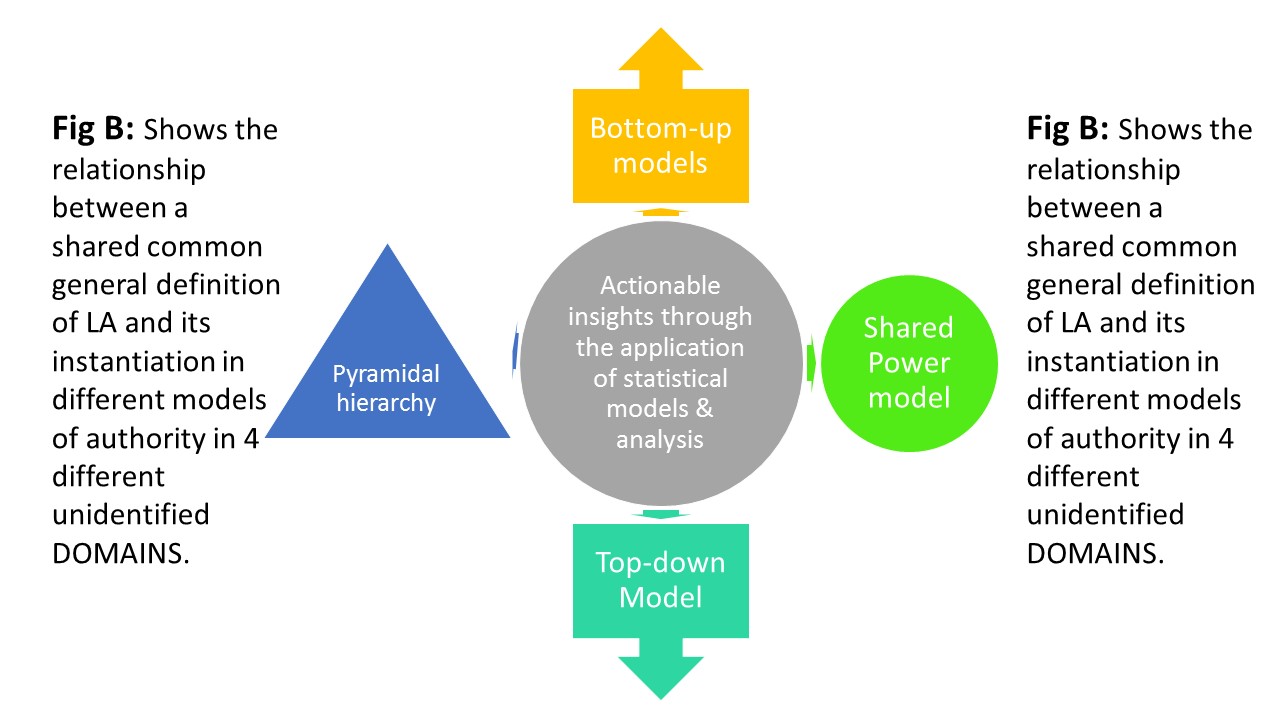
Note in your learning
journal or blog which of these questions can be considered:
a.data driven
b.pedagogy driven.
Teaching and learning exercises often come from above (by a
course, textbook author or a teacher) and arrive on the learner’s ‘to do’ list
unbidden and not fully understood. The exercises from Block 4, Nos. 7 – 9 appear to
be one such instance. Constructing in 7 a
concept called ‘data-driven questions’ and in 8 ‘pedagogy driven' equivalents,
this question asks you to test these constructed concepts on a number of
questions not devised for that purpose and included in a paper that does not,
fundamentally, require you to make this distinction.
No wonder then, one might
think, it will be possible to have questions and declarative statements (the 2
source tables carry each respectively) that do not meet the constructed
criteria.
On top of this, we must treat the declaratives in Table 4 as if they
were questions like those in Table 2. To do this, you would have to rephrase
the latter and, in that act, might lie some of the variables that will impinge
on their categorisation. Thus: ‘Learning analytics (LA) is supposed to track
user activities’, could be phrased, ‘What user activities is LA supposed to
track?’, or ‘Why is LA supposed to track user activities?’. These two questions
have a different degree of implicit (at the least) pedagogical concern behind
them but perhaps the second demands answers that address some active purpose,
perhaps even that of pedagogy.
I explain that at length because I’m embarrassed by not
wanting to try to meet the requirement of this activity. It feels to me not to be a
useful exercise and I feel my time is limited by the demands of a TMA that I
can meet in other ways (such as by reading Dyckhoff et. al. 2013 critically and
discussing it, rather than concentrating on 2 of its tables mainly). Of course, the
issues of import might no doubt come out in discussion but it strikes me that
each learner needs to have some trust and some way of pre-evaluating exercises given
to them. So, at the cost of seeming difficult, I feel I have to express this.
In the pre-amble to Activity 8 where ‘pedagogy driven
analytics’ are defined, we are told that:
“This
approach uses the pedagogy of a course to help frame and focus questions that
can be answered by analytics:”
This definition
begs so many questions. Different pedagogical theories stress different ways of
framing questions and have a different view of the kind of data and evidence
that might be used to answer them. Many courses use multiple pedagogical
theoretical strands in the definition of what they do. Therefore, the best
approach to this isn’t, I believe, the work expended on Activities 7 – 9 but
taking seriously the reading offered to us as learners, particularly learners
operating at a Masters’ level.
In Dyckhoff
et. al.’s (2013:220) introduction, the authors make a distinction that is like
that between ‘data versus pedagogy driven’ (which clearly somebody understands on this module or these activities would not have survived)
but easier to grasp and to implement in Activity 9 than the former. We are told
there that LA, as opposed to action research, devises categories that may be
used as indicative of events (what they are it doesn’t at this point ask) :
‘Hence the indicators might solely represent information
that depends on the data-sources used, e.g. by just making the data visible
that has been “unseen, unnoticed, and therefore unactionable ... ‘(whilst
action research thinks) ‘… about the questions that have to be answered before
deciding about the methods and data sources.’
That in a
nutshell is the distinction we need to understand the relationship between
research into pedagogy and the provision of data that may or may not be important in understanding pedagogic practices. Yet
the published piece makes this absolutely clear distinction without introducing
the concept of ‘drive’ or ‘motivation’. In what sense can data ‘drive’ a
question, such that it does not demand that further questions are asked?
I want to
take one example from Table 2 (c) which intrigues me, and I’ll try out the
activity on it, in a manner the issue deserves (it is after all a question
about the politics of educational provision):
‘Do Native speakers (NS) have fewer problems with
learning offerings than non-native speakers (NNS)?’
On the
surface this merely asks for a quantitative answer, provided of course we can
agree on an operational definition of a ‘learning offering’ and a ‘problem’. In
effect both would be extremely difficult to operationalize without
consideration of matters of teaching and learning.
Let’s assume
though that we know what we mean by both terms, such that NS have x problems and NNS have y. Suppose further y > x. We have a piece of visible data about which action could
occur – but what action? Clearly this then is data-driven! Well, yes, it is
- provided we already know that data on ‘problems’ with ‘learning offerings
already exist. Perhaps we have decided that such problems can be represented by
the number of queries made to the tutor.
As we go on
piling on assumptions here, we see that we can’t have avoided pedagogic
questions, even though we did not include them explicitly in the question. For
instance, what constitutes a ‘learning offering’ to a NNS will depend on how
well the ‘offering’ has accommodated itself to their pre-known needs.
What
scenario does this question address? Let’s imagine that it addresses a class of
15 year olds in Germany containing a mix of ethnic groups. In each ethnic group
there are speakers (people from Turkey, Somali, Tunisia – speaking both French
and Arabic but no German) and who use English for different reasons if they use
it all and at different levels of competence in relation to its purpose. The ‘learning
offering’ we are considering is a scene from Bertolt Brecht’s ‘The Caucasian
Chalk Circle’ to begin conversation on the meaning of ‘being native’.
Could a ‘learning
offering’ be constituted by giving all the class the ‘scene’ in a photocopied
text in the original German? Would not such ‘problems’ that might arise not
have been predicted from the very beginning of the teacher’s preparation. In
doing so, has s (he) provide different resources for different groups – used the
differentiation principle in teaching theory.
So where
does the distinction get us. This question demands a data-based answer perhaps
but you would ask it without knowing the difficulties that already interact in
the way we define ‘learning offering;’ and ‘problem’ - implicit questions of
pedagogy.
And then we
get to what the reading might have offered us without the activity as, I
believe, an unintended distraction. That is that research orientations to data
focus on research questions while ‘learning analytics’ does not necessarily do
so. There, it’s easy!
Further, we
learn about pedagogy by asking questions about its experimental implementations
and seeking methods and data to answer these questions not merely ‘eyeballing’
(as we psychologists have it) newly visible data without such appropriate
questions. In the end the action demanded of insight is to validate and maintain
or find evidence of something wanting and change that pedagogical approach or
an element of that approach.
I think reading
the paper set could bring us to this insight but equally I think the activity
might have done that too (for some people). What it could not have done so
easily is raise the issue in Dyckhoff et. al. (2013:22) that perhaps learning
analytics (even if entirely ‘data-driven’) can add something to (pedagogy-driven)
action research that we would not have got from action research (or the ‘pedagogy-driven)
alone.
With more practice of LA in everyday life, other ways
might appear to measure the impact of LA.’
That is what
I’m missing in our activity – the sense that ‘big data’ is emergent and may
raise questions that research methods, as we currently know them, would not. I
don’t know. However, this is precisely what some claim and what I would like to
know more about from this module. After all LA is already statistically driven –
by virtue of the correlations it makes available to us. At this point, the
researchers jump in – but ‘correlation is NOT CAUSATION’. Of course. But witness
this claim from Mayer-Schönberger & Cukier (2013: Loc 234):
In a big-data world, we won’t have to be so fixated on
causality; instead we can discover patterns and correlations in the data that
offer us novel and invaluable insights. The correlations may not tell us
precisely why something is happening, but they alert us that it is happening.’
With that
claim goes another. We would not have been thus alerted from research process
alone – at least not in a timely manner. This is something I want to know
about.
In Collins
& Stone (2014) librarians at the University of Huddersfield (where I come from - Huddersfield that is, not the University) discovered that
huge discrepancies between a range of indicators of library use across
different disciplines that did not match previous research. This led them to
understand that local issues – almost certainly ones differentiating the
pedagogic approaches of different disciplines had driven this finding otherwise
invisible to them. The next step is research based on questions – but the
questions would not have come about at all without the big data.
Collins, E. & Stone, G. (2014) ‘Understanding
patterns of library use among undergraduate students from different disciplines’
in Evidence-Based Library &
Information Practice 9 (3) 51 – 67 ISSN 1715-720X.
Dyckhoff, A.L., Lukarov, V., Muslim, A., Chatti, M.A.
& Schroeder, U. (2013) ‘Supporting Action Research with Analytics’ in Proceedings of the 3rd
International Conference on Learning Analytics and Knowledge (LAK’13) 220 –
229.
Mayer-Schönberger, V. & Cukier, K. (2013) Big Data: A Revolution that will transform
how we live, work and think London, John Murray.




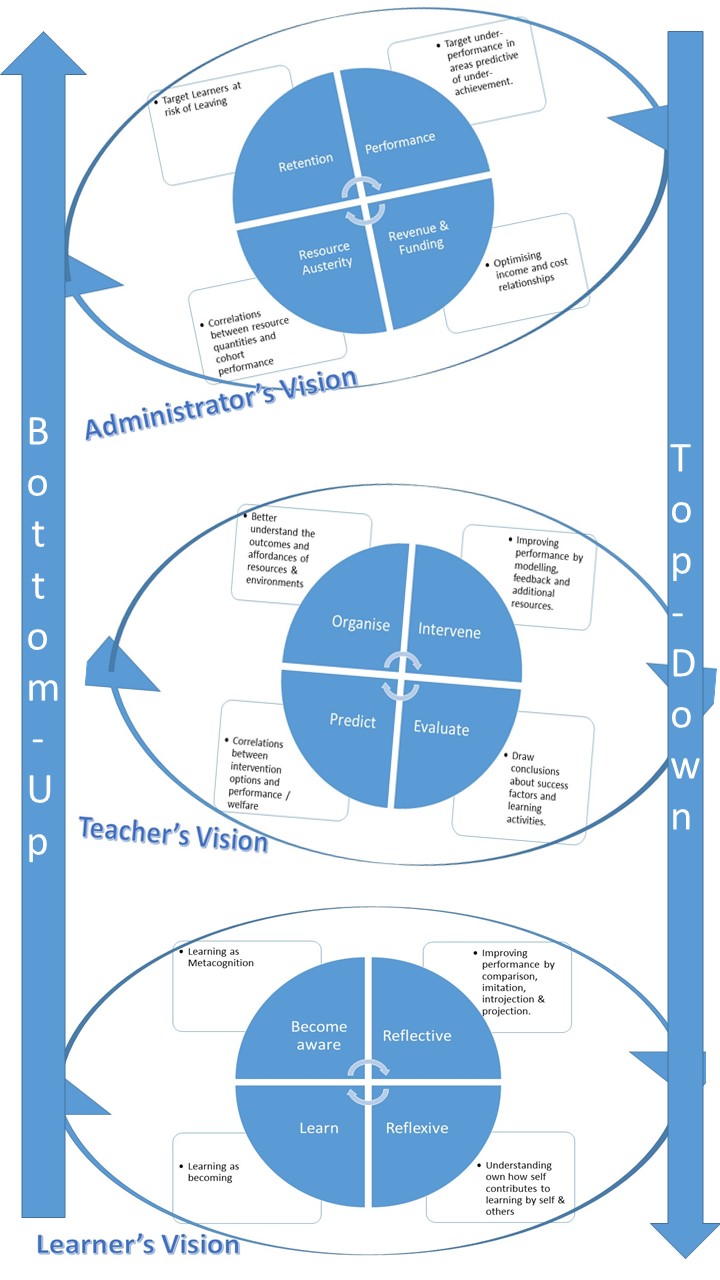
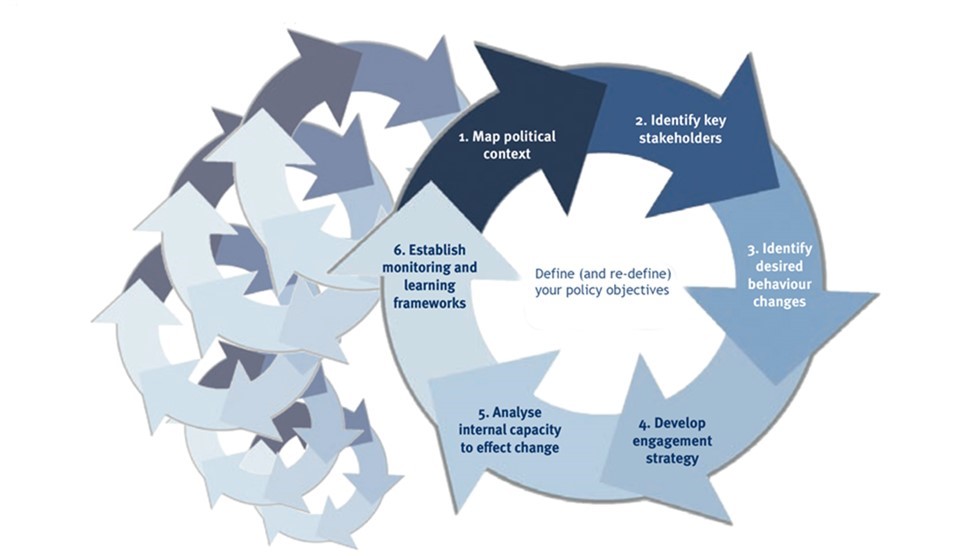
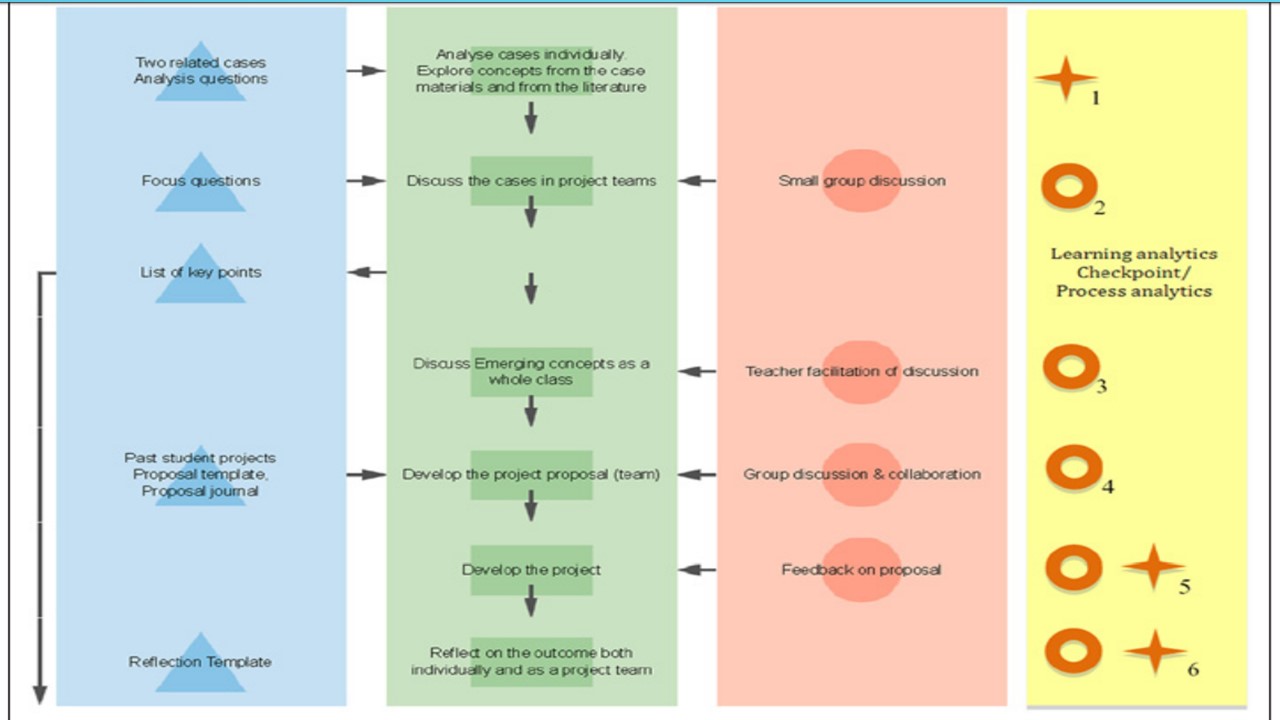
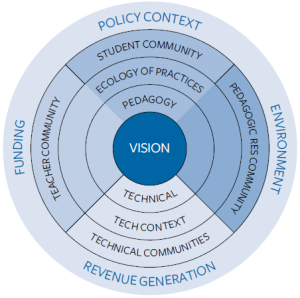 This is Fig.1 from Scanlon et. al. (2013:29)
This is Fig.1 from Scanlon et. al. (2013:29)